Last week I was in Melbourne for Web Directions - AI Engineer. I was interested in hearing from people using AI day-to-day, and the ups and down of it. As I usually do, I took a bunch of notes.
My takeaways
I went to about half the talks, splitting my time between the Software Engineering and AI Engineering tracks. A few themes came up across the talks I was at.
Practical
- Choose the right model for the task
- Use a frontier model when things are subjective, ambiguous, and we have sparse feedback. This can be slow and expensive.
- Use a lower-end model when things are objective, clear, and we can loop with good feedback. This can be fast and cheap: error improvement compounds.
- Most of the time, start with a model in the middle
- Right context beats more model
- Use a versioned learning loop
- Documents that AI uses have to be keep very up-to-date to stay and relevant and helpful
- The spec, the AGENTS.md, skills, Confluence pages
- The spec becomes the source of truth
- Version control these changes like we version control our code
- Documents that AI uses have to be keep very up-to-date to stay and relevant and helpful
Theoretical
- Treat LLMs with caution
- There will always be some confabulation, even with excellent prompt engineering
- The LLMS should not act as a boundary (for privacy, security, etc). Our application (architecture) should be.
- Stories, prompt injection, can change the success condition: failure is always nearby
- AI use must earn the right to scale. Start small and have a progressive rollout.
- There are many pieces, and they’re all connected
- The model, the prompt, the harness, etc.
- AI helps with coding, but that’s only a small part of an engineer’s job
- No magic wands
- Bottlenecks/constraints don’t disappear, they just move
- Removing waste is (still) the biggest accelerator: more than AI
Sketchnotes

Day one - sketchnotes page 1
State of the AI Landscape - George Cameron
Cheaper intelligence but/and Higher spend than ever
Token Town: why token strategy is product strategy - Sarah Sachs
- Build the best product that uses any model instead of training the best model
- Optionality is leverage
- Open weight models are now strong enough for moderate tasks
- What moderate means is contextual
Everything is a Factory - Geoff Huntley
- Everyone is now a software developer → The job has been commoditised
- It needs Deliberate intentional practice, like an instrument
- Curiosity-test people
- Removing waste is the biggest accelerator (more than AI)
Three lanes below one millisecond - Vamsi Ramakrishnan
Full-duplex voice punishes the mistakes that text-only forgives.

Day one - sketchnotes page 2
Fail fast, fix faster: why faster models can beat smarter ones
- Good enough, but fast
- Especially for Ralph loops, with good feedback
- Cheap error detection
- Especially for Ralph loops, with good feedback
- Implement → Validate → Inform, loop
- A bit like Test-Driven Development
- Error improvement compounds
- Use a frontier model when: subjective, ambiguous, sparse feedback
Why AI coding tools might not make the slightest difference - Jason Cornwall
- They say about 10% increase in productivity 2024-2026
- Every system has exactly one constraint
- but/and it moves!
- when you remove one
- Coding is about 15% of an engineer’s time
- The others are failure-avoidance activities
- AI as an ingredient, not the recipe
Constitutional prompting - Prem Pillai
- Your agents is already making decisions - just not ones guided by you
- You can debug a spec. You can’t debug vibes.
From zero to production - Rachael Zhang
Do progressive rollout: earn the right to scale

Day one - sketchnotes page 3
Agent observability - Daniel Nadasi
- Look at every level, once per framework
- Tighter controls means easier observability
Our AI hallucinated in Production: how we fixed it with evals - Yicheng Guo
- Hallucination (of property features) rate: 5%
- even after much prompt engineering
- Learning system
- Software metrics
- Human judge - lots of labels
- LLM judge - trained from human’s labels
The application layer is the new research lab
- The prompt is just one piece of many
- Behaviour is joint
- We only own a function of the pieces, not the pieces themselves
Orbital lasers vs For loops: economically matching models to tasks - Stephen Sennett
- We don’t choose, we default
- The range
- \(\)$ Words matter (about 10% of the time)
- $$$ Structured, but logical (about 70% of the time)
- Failure? Retry with \(\)$ model
- $ Make simple things fast (about 20% of the time)
- Best fit, best tool
- Not overuse or hallucinate
- Right context beats more model
- Documentation, MCPs
Your AI can’t engineer (yet) - Theo Galanos
- One number can’t tell the whole story
- Model: the reasoning; harness: everything else!
Day two - sketchnotes page 1
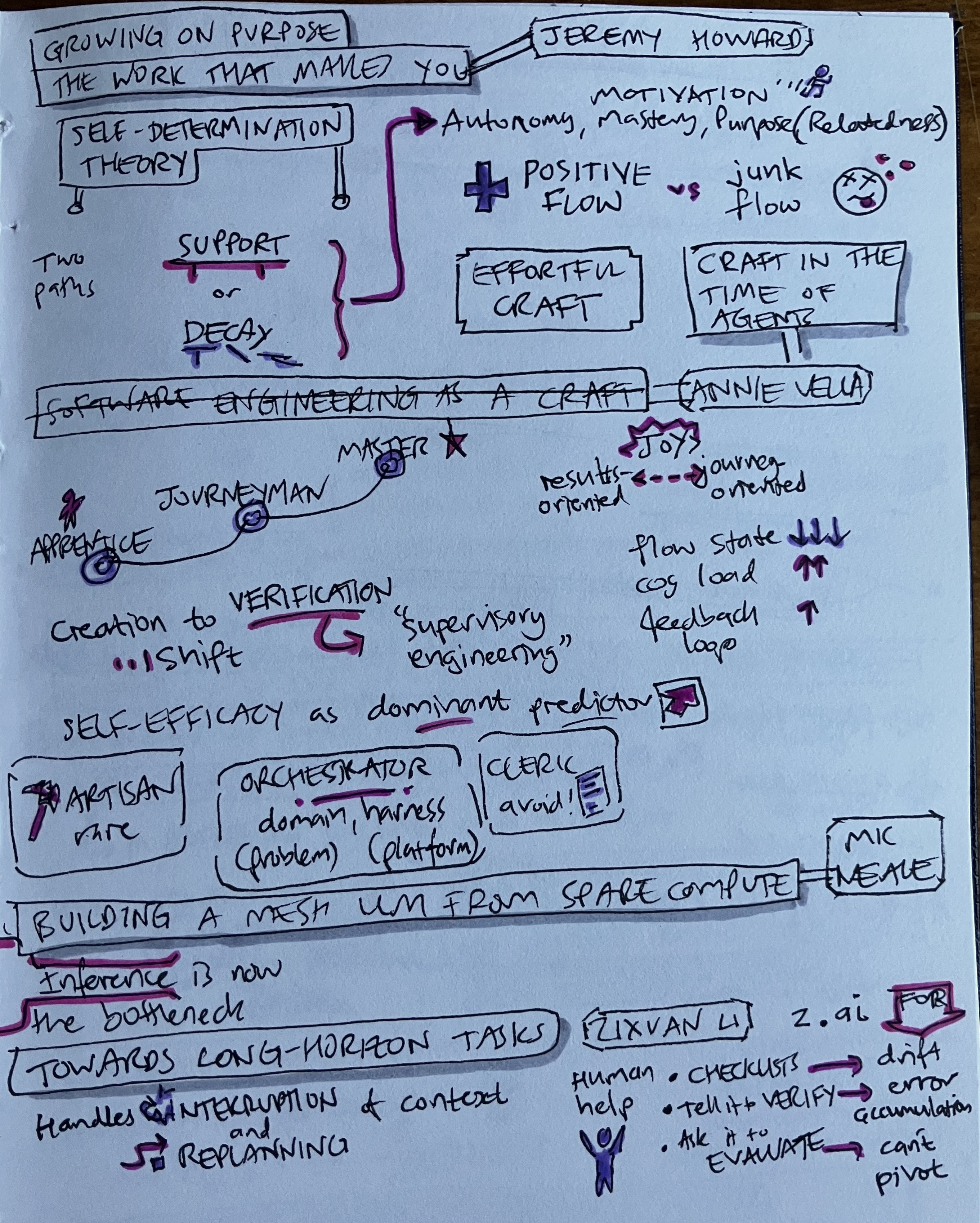
Growing on purpose: the work that makes you - Jeremy Howard
- Self-determination theory
- Two paths: support or Decay
- Autonomy, Mastery, Purpose, Relatedness
- Effortful craft
Craft in the time of agents - Annie Vella
- Apprentice → Journeyman → Master
- A spectrum between results-oriented and journey-oriented
- Creation to verification (“supervisory engineering”) shift
- Effects
- Flow state ↓↓↓
- Cognitive load ↑↑
- Feedback loop ↑
- Self-efficacy as a dominant predictor
- Three models
- Artisan. Rare.
- Orchestrator
- Domain (problem) and harness (platform)
- Clerk. Avoid!
Buidling a mesh LLM from spare compute - Mic Neale
Inference is now the bottleneck.
Towards long-horizon tasks - Zixuan Li
- Handles interruption and replannings of context
- Human help
- Checklist for addressing drift
- Tell it to verify for addressing error accumulation
- Tell it to evaluate for when it can’t pivot
Day two - sketchnotes page 2
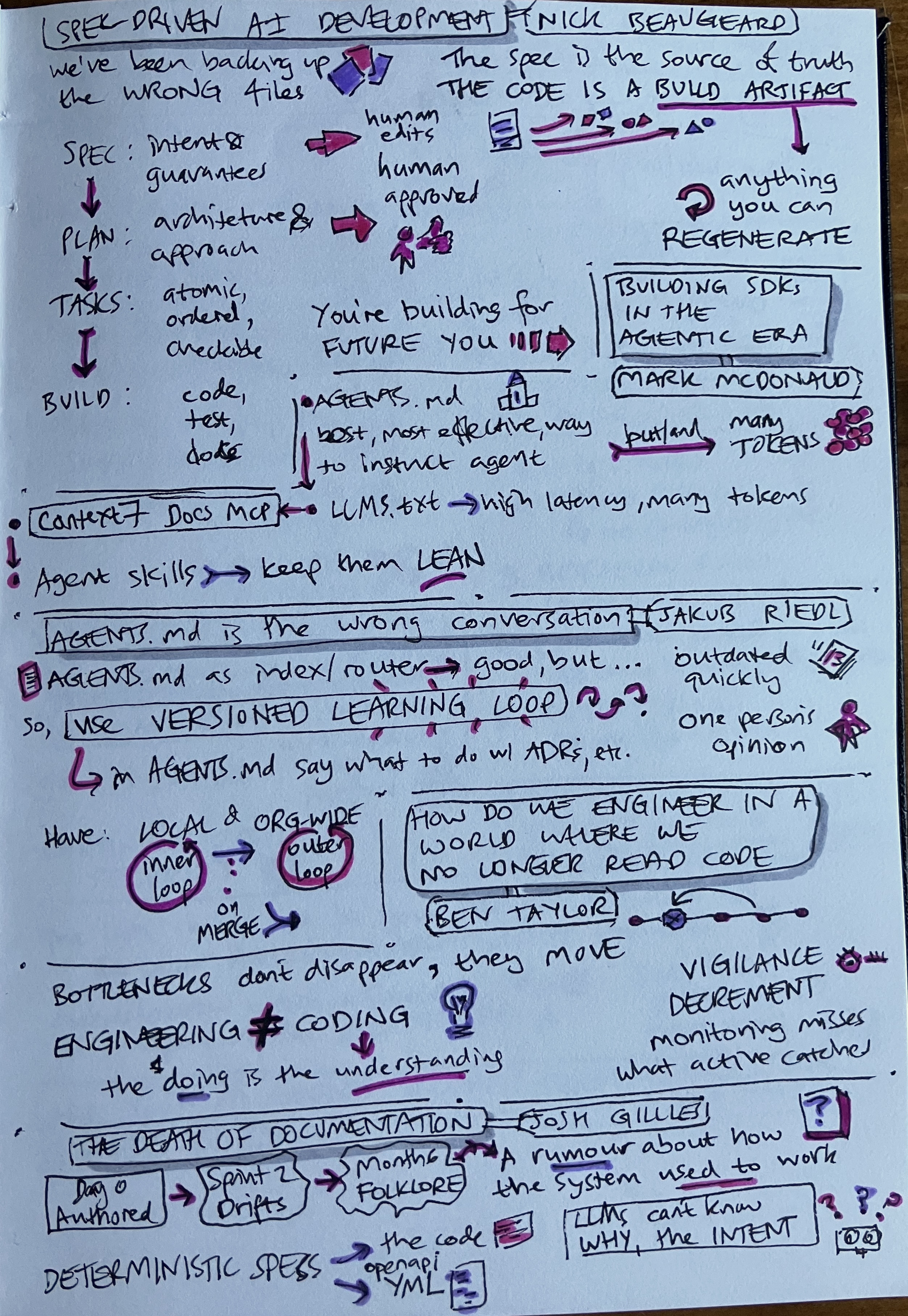
Spec-driven AI development - Nick Beaugeard
- We’ve been backing up the wrong files
- The spec is the source of truth. The code is a build artefact.
- Anything you can regenerate is an artefact.
- The process
- Spec: intent and guarantees
- Edited by a human
- Plan: architecture and approach
- Approved by a human
- Tasks: atomic, ordered, checkable
- Build: code, tests, docs
- Spec: intent and guarantees
Building SDKs in the agentic era - Mark McDonald
- AGENTS.md is the most effective way to instruct an agents, but/and uses many tokens
- LLMS.txt has high latency, uses lots of tokens
- Agent skills - keep them lean
AGENTS.md is the wrong conversation - Jakub Riedl
- AGENTS.md as an index/router - good, but …
- it gets outdated quickly
- it’s one person’s opinion
- Use a versioned learning loop
- in AGENTS.md say what to do with ADRs, etc.
- Have an inner/local loop and an outer/organisation-wide loop
- Share to the outer loop on merge
How do we engineer in a world where we no longer read code - Ben Taylor
- Bottlenecks don’t disappear, they move
- Engineering ≠ Coding
- The doing is the understanding
- Vigilance decrement: monitoring misses what active catches
The death of documentation
- The pattern
- Day 0 it’s documented
- Sprint 2 it drifts
- Month 6 it’s become folklore
- A rumour about how the system used to work
- LLMs can’t know the why, the intent
- Deterministic specs
- the code
- openAPI yml

Day two - sketchnotes page 3
Designing inference-native systems - Sajjad Kamal
- Update belief → Decide → Act
- Intent (decisions, stories), Context, Action, Reconciliation, Verification
Why LLMs fall for stories - Mal Curtis
- Can get outside the guardrails
- Chat is still a prompt
- Reasoning is more text
- Stories can flip the success condition
- The opposite is nearby
- Failure is nearby
- The opposite is nearby
- Stages of guardrails
- Input rails
- Dailog rails
- No changing jobs
- Retrieval rails
- Evidence, not instructions
- Execution rails
- Tools behind policy, not prose
- Outout rails
- Verify the answer
Hacking the model: AI Red Teaming in practice - Pas Apicella
- Goal + Strategy
- Fractured, ever-evolving, attack surface
- Continuous Offensive Security
Why most AI De-identification fails in production - Moin Zaman
- The LLM should not be your privacy boundary
- Your application architecture should be
- Manual review wasn’t a fallback. It was part of the architecture.
- Don’t hide uncertainty from users